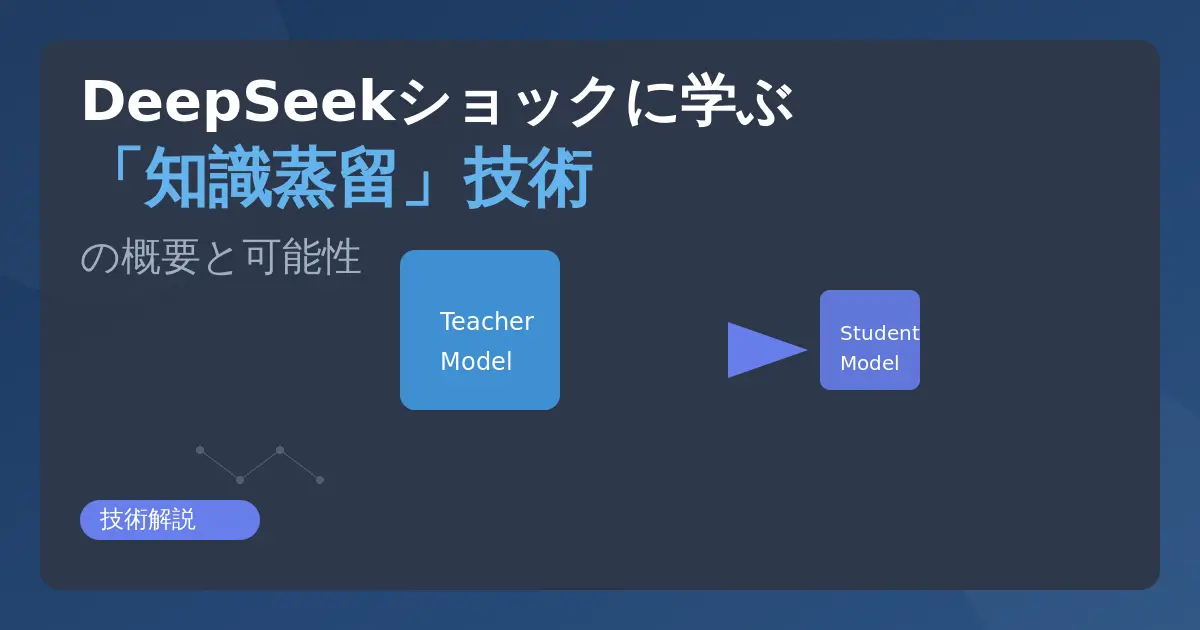
蒸留技術の概要:知識蒸留とは何か
知識蒸留(Knowledge Distillation)とは、大規模な教師モデル(teacher)が持つ知識や判断基準を、小型で効率的な生徒モデル(student)に移し替える学習プロセスです。要するに、性能の高い教師モデルの出力(予測確率分布)を活用して、生徒モデルがその振る舞いを真似るように訓練します。例えば画像認識で犬の画像を入力した際に、教師モデルが「トイプードル90%、ビションフリーゼ10%」といったSoft Targets(ソフトな目標分布)を出力したとします。このソフトターゲットには単なる正解ラベル以上の情報が含まれており、生徒モデルはそれを参考にすることで教師モデルの判断基準を学習できます。知識蒸留の狙いは、モデルの軽量化と高速化にあります。巨大なニューラルネットワークは高精度な予測が可能な反面、推論に莫大な計算資源やメモリを要します。蒸留によりこうしたモデルを小型化すれば、性能をほとんど損なわずに低コストなハードウェア上でも動作させることができます。主なメリットをまとめると:
- モデルの小型・省メモリ化:教師モデルの知識を圧縮し、生徒モデルのパラメータ数を削減できます。これによりメモリ使用量が減り、デバイス上での実装が容易になります。例えば、BERTを圧縮して得られたDistilBERTはパラメータを40%削減しつつも性能の97%以上を維持しています。
- 推論の高速化:生徒モデルは層が浅くパラメータも少ないため、計算が高速化します。DistilBERTではモデルサイズ縮小に伴い推論速度が約60%向上したとの報告があります。これによりリアルタイム応答が求められるアプリケーションでも高性能モデルを利用しやすくなります。
- 学習コストの削減:教師モデルが生成した追加データや出力を活用することで、一から大規模データで学習するよりも効率良くモデルを訓練できます。高精度モデルの知識を“蒸留”することで、生徒モデルは比較的少ないデータや計算資源で高い性能を発揮できるのです。
- 応用の幅の拡大:蒸留により得られた軽量モデルはモバイル端末やエッジデバイスへのデプロイが容易になります。また、複数モデルの知見を単一モデルにまとめる「アンサンブルの蒸留」など応用手法も研究されています。これらにより、強力なAIをより身近な環境で活用できるようになります。
以上のように知識蒸留は、”大きなモデルの知恵を小さなモデルに継承する”ための技術です。2015年にHintonらが提唱して以来広く研究され、自然言語処理や画像認識など様々な分野でモデル圧縮の標準的手法となっています。性能と効率のトレードオフを最小化できる点で、現代のAI開発における重要なテクニックとなっています。
DeepSeekと2025年1月27日のNVIDIA株価への影響
2025年1月末に発生した「DeepSeekショック」は、知識蒸留技術の威力を世間に知らしめました。中国のAIスタートアップDeepSeek社が開発した大規模言語モデル「DeepSeek R1」は、無料公開のオープンソースモデルでありながら、有料で提供されているOpenAIの高度なモデル(コードネーム「o1」)に匹敵する性能を示しました。R1は2025年1月20日にリリースされるやいなやAIコミュニティで話題沸騰となり、iPhoneのAppStore無料アプリランキングでChatGPT公式アプリを追い抜いて1位になるほど注目を集めました。この「AI版スプートニクショック」とも称される出来事が、半導体業界にも波紋を広げたのです。
特に影響を受けたのがGPUメーカーのNVIDIA社でした。DeepSeek R1の登場によって、「高性能AIモデル開発にこれまでほど大量の最新GPUは不要になるのではないか」という懸念が広がりました。実際、OpenAIのモデル開発には最先端GPUを数万個投入し数億~十億ドル規模の費用がかかるとも言われます。ところがDeepSeekは、米国の輸出規制で最新GPUが使えない中、あえて性能抑制版のNVIDIA H800チップをたった2048枚用いて、OpenAIのGPT-4やo1とほぼ同等性能のLLMを作り上げました。その開発費はわずか約560万ドル(約8.7億円)と、米国勢の1割以下(報道によればOpenAIモデルのわずか3%程度)に過ぎません。この驚異的な低コスト・高性能開発のニュースに投資家は衝撃を受け、2025年1月27日の米株式市場ではNVIDIA株が前日比16.9%の急落となりました。わずか一日で時価総額5888億ドル(約91兆円)が吹き飛び、世界時価総額ランキング1位だったNVIDIAは3位に転落しています。同日のナスダック総合指数も3%以上下落し、他のAI関連株(Broadcom -17%、AMD -6%など)や関連インフラ企業の株価まで軒並み急落するパニック売りとなりました。この一連の株価暴落は文字通り「DeepSeekショック」と呼ばれ、AIブームを支えてきたハードウェア業界に一石を投じたのです。
株式市場がこれほど過敏に反応した背景には、知識蒸留という技術への期待と不安がありました。DeepSeekの技術革新によって「AI開発の計算資源への依存度が低下するのでは」という見方が広がり、GPU需要の伸びに陰りが出る可能性が意識されたのです。実際R1の成功は、今後は必ずしも巨額の投資や最新GPUを独占しなくても最先端AIを開発できることを示唆しています。しかし一方で、「蒸留」による性能への評価は専門家の間でも分かれており、必ずしもNVIDIAの優位が直ちに崩れるわけではないとの指摘もあります。後述するように、R1は確かに画期的な成果ですが、それだけでゲームチェンジャーになるかはまだ見極めが必要という冷静な見方もあるのです。
簡単なコード例:知識蒸留の実装
では、知識蒸留とは具体的にどのように行うのでしょうか。基本的なアイデアは「教師モデルの出力分布を、生徒モデルの学習目標にする」ことです。つまり、従来の正解ラベルとの誤差に加え、教師モデルの予測確率との誤差を損失関数に含めます。以下にPyTorchベースの簡単な疑似コード例を示します。
import torch
import torch.nn.functional as F
teacher_model.eval() # 教師モデルは学習済み(更新しない)
T = 2.0 # 温度パラメータ:出力分布を平滑化
alpha = 0.5 # 蒸留損失の重み(0~1で調整)
for inputs, labels in train_loader:
# 教師モデルの予測分布(ソフトターゲット)を取得
with torch.no_grad():
teacher_logits = teacher_model(inputs)
teacher_probs = F.softmax(teacher_logits / T, dim=-1) # 温度Tでsoftmax
# 生徒モデルの予測を取得
student_logits = student_model(inputs)
student_log_probs = F.log_softmax(student_logits / T, dim=-1)
# (1) 知識蒸留の損失:教師と生徒の出力分布の差異(KLダイバージェンス)
loss_kd = F.kl_div(student_log_probs, teacher_probs, reduction='batchmean') * (T**2)
# (2) 通常の分類損失(正解ラベルとのクロスエントロピー)
loss_ce = F.cross_entropy(student_logits, labels)
# 2つの損失を重み付きで合算し、生徒モデルのパラメータを更新
loss = alpha * loss_kd + (1 - alpha) * loss_ce
optimizer.zero_grad()
loss.backward()
optimizer.step()
上記コードでは、まず教師モデルの予測確率分布teacher_probsを計算し、それに生徒モデルの出力student_logitsを近づけるような損失loss_kdを計算しています。具体的にはKLダイバージェンス(またはそれに類する損失)によって、生徒の確率分布が教師の分布を模倣するように訓練します。同時に、生徒モデル自身も正解ラベルに対して分類誤差loss_ceを小さくするよう学習します。損失全体は蒸留損失と通常の損失の加重和で表され、ハイパーパラメータalphaによってバランスを調整します。また、T(温度)は出力分布の滑らかさを調節するパラメータで、通常は教師と生徒の両方に適用します。高い温度を用いると教師の予測分布がなだらかになり、自信度の低いクラスにも情報が含まれるようになります。この情報を生徒に学習させることで、ただ正解を当てるだけではなく、教師モデルが持つクラス間の暗黙的な知識まで引き継ぐことができるのです。
このように実装された知識蒸留により、生徒モデルは教師モデルに近い判断ができるようになります。例えば上記の手法で大規模モデルの知識を蒸留すれば、小型モデルでも教師とほぼ遜色ない精度が得られることが期待できます。実際に、蒸留を行った生徒モデルは行わなかった場合に比べテスト精度が大きく向上することが知られています。
コストの優位性と技術の可能性
蒸留技術によるコスト削減効果
DeepSeek R1の事例が示すように、知識蒸留はAIモデル開発のコスト構造を劇的に変える可能性を持っています。R1はOpenAIのモデルに比肩する性能を持ちながら、その訓練コストは数%程度(約1/30)に過ぎませんでした。この大幅なコスト削減を可能にした要因の一つが、蒸留による効率的な学習です。
通常、高性能な大規模モデルをゼロから訓練するには莫大な計算リソースとデータが必要です。しかし蒸留を活用すれば、既存の強力なモデルを教師役とし、その知見を生徒モデルに移すことで学習プロセスを短縮できます。例えばDeepSeekは、事前に優れたLLM(OpenAIのGPT系モデル)に大量の質問を投げかけて得られた回答データを訓練用に利用したとされています。このように教師モデルが生成した高品質な疑似データで学習することで、一から人手でデータ収集・ラベル付けするコストを省けます。また学習に用いるステップ数やエポック数も削減でき、結果として必要なGPU時間が大幅に減少します。その成果が、わずか2ヶ月でのR1開発や、600万ドル程度という破格の開発費につながったわけです。
知識蒸留はまた、推論コスト(利用時の計算資源)の面でも優位性があります。小型化したモデルは動作時に必要な計算が少なく、クラウド上のGPU使用料や電力消費の削減につながります。モデルが軽量になることで、1台のサーバでより多くのリクエストを処理できたり、エッジデバイス上で完結して動作できたりするため、トータルの運用コストも下がります。実際、前述のDistilBERTではモデルサイズ縮小により60%の推論速度向上が報告されており、これは同じハードウェアでより高速に、あるいはより少ないハード資源で同等速度を実現できることを意味します。
さらに近年の研究では、極端に少ないデータでも蒸留を成立させる試みが登場しています。スタンフォード大学などの研究者グループは、たった1000件の厳選されたQ&Aデータ(高性能モデルが生成した回答とその思考過程)で大規模モデルを蒸留し、高性能を発揮させることに成功しました。この手法では訓練にかかったコストは数ドル相当と試算されており、蒸留によるコスト削減効果の大きさを象徴しています。今後、教師モデルの知識をいかに効率よく抽出・圧縮するかが進歩すれば、「数千円の費用でChatGPTレベルのモデルを作る」ことも現実味を帯びてくるでしょう。
現在のLLMにおける知識蒸留の役割
知識蒸留は現在の大規模言語モデル(LLM)開発において重要な役割を果たし始めています。モデルサイズが数十億~数千億パラメータに及ぶLLMでは、そのままでは扱いづらく、計算資源が限られる場面での利用が難しいという課題があります。そこで、LLMを蒸留して小型モデルを作成し、性能を維持したまま扱いやすくする取り組みが盛んです。
実例として、Meta社の公開した大規模モデル「LLaMA」シリーズでは、コミュニティが蒸留や微調整を駆使して派生モデルを数多く生み出しました。スタンフォード大学のAlpacaプロジェクトでは、OpenAIのモデル(テキスト生成API)の出力した指示応答データをLLaMA 7Bモデルに学習させ、驚くほどChatGPTに近い対話性能を実現しました。これは蒸留の一種であり、大型モデルの応答を小型モデルに覚えさせることで、元のモデルの知識と言語生成能力を継承したものです。このようなオープンソースLLM + 蒸留の組み合わせにより、大学や企業、個人ですら比較的低コストで高機能なチャットAIを作れるようになってきました。
また、大規模モデル開発企業自身も蒸留を活用しています。Googleはモデル圧縮のために蒸留を用いており、OpenAIや他社も推論用の軽量モデルを内部で蒸留によって作成しサービス展開しているとされます。要するに、蒸留なくして現在のLLMの普及は語れない状況になりつつあります。現代のチャットAIアプリがスマートフォン上で動作したり、オープンソースの対話モデルが次々登場したりしている裏には、必ずこの知識蒸留のテクニックが貢献しているのです。
DeepSeek R1も、まさにその潮流の象徴と言えます。DeepSeekは知識蒸留によって、従来なら中国国内では入手困難だったOpenAIの最先端モデルに迫る能力を自社モデルに与えることに成功しました。さらにR1をMITライセンスで公開(商用利用・改変も自由)したことで、誰もがそのモデルをダウンロードして使えるようになりました。これはChatGPTのようなクローズドなモデルとは対照的で、オープンソースコミュニティによる改良や応用が可能です。実際、R1公開後に世界中の研究者・開発者がこのモデルを検証し、日本語能力を高めるファインチューニングを行うなど派生プロジェクトも登場しています。知識蒸留は、LLM開発を一部の巨大企業からより多くのプレイヤーへと開放し、AIの民主化を進める原動力になりつつあるのです。
ChatGPTを超える可能性と必要な技術革新
最大の関心事は、「蒸留技術でChatGPT(GPT-4相当)を超えるモデルを作れるのか?」という点でしょう。結論から言えば、知識蒸留だけで教師を凌駕するのは容易ではないものの、条件次第では部分的に超える可能性も考えられます。
DeepSeek R1に関して言えば、一部メディアは「ChatGPT超えの中国AI」とセンセーショナルに伝えました。実際、OpenAIのo1(ChatGPTの基盤モデルと推測される)に肉薄する性能を見せたことは事実です。しかしR1が現時点でGPT-4水準のChatGPTを全ての面で上回ったと断言するのは難しく、性能比較はタスクや評価基準によって異なるのが現状です。例えば言語の流暢さや知識量、創造的応答といった総合力では依然としてGPT-4ベースのChatGPTが勝る場面も多いでしょう。一方でR1はオープンソースである利点を活かし、ユーザが自由にチューニングできるため特定領域の知識を追加するなどカスタマイズ面でChatGPTを超える可能性があります。
知識蒸留の原理上、生徒モデルの能力の上限は教師モデルの能力に依存します。教師以上の知識は与えられないため、単にChatGPTの出力を蒸留するだけではChatGPTと同等か若干劣る性能のモデルが得られるのが一般的です。しかし、いくつかのアプローチでこの限界に挑戦できます:
- 複数教師の活用: 例えばOpenAIのChatGPTに加え、他社の強力モデル(GoogleのGeminiなど)や専門特化モデルからそれぞれ知識を蒸留し、良いとこ取りした生徒モデルを作る研究が考えられます。複数の教師から多様な知見を統合できれば、単一のChatGPTを上回る総合力を発揮できるかもしれません。
- 独自データとの併用: ChatGPTからの蒸留に加えて、最新の知識や独自収集した高品質データで追加訓練すれば、ChatGPTが持っていない情報や能力を生徒モデルに付加できます。例えば最新の時事情報や専門分野の知識を与えることで、特定の質問に対してChatGPT以上に正確な回答を出せるようになる可能性があります。
- モデルアーキテクチャの改良: 生徒モデル自体のネットワークアーキテクチャを工夫し、より少ないパラメータでも表現力を高める研究も重要です。もし教師モデルよりも効率的な構造を作れれば、蒸留後に教師を凌ぐ性能を示せる余地があります。これは長期的な基礎研究の課題ですが、例えば特殊な自己注意機構やメモリ機構を備えたモデルで知識を蒸留すれば、コンパクトでも高度な推論が可能になるかもしれません。
もっとも、現時点ではChatGPT(特にGPT-4モデル)の壁はなお高いと言えます。OpenAI自身も常に改良を続けており、R1が追いついたとされる「o1」に対してさらに上位の「o3」モデルを近日リリース予定とも報じられています。つまり、教師側も日進月歩で進化しており、単に現状のChatGPTに追いつくだけではすぐにまた差が開いてしまう可能性があります。蒸留モデルが真にChatGPTを超えるには、絶え間ない教師モデル側のキャッチアップか、あるいは異なる発想のブレークスルーが必要でしょう。
興味深いことに、DeepSeekの台頭に対し米国の専門家からは冷静な評価も出ています。投資会社AllianceBernsteinのアナリストは「DeepSeekのモデルは素晴らしいが奇跡というほどではなく、『我々が知るAIインフラの終焉』といったパニックは誇張だ」とコメントしています。要するに、ChatGPTやNVIDIAに代表される西側のAIエコシステムが直ちに覆るわけではないという見解です。実際、NVIDIAもAI半導体の改良を続けていますし、OpenAIや他の企業も次世代モデル開発にしのぎを削っています。DeepSeekショックは一時的な揺らぎに過ぎず、長期的には「大規模モデル vs 蒸留小型モデル」の健全な競争が続くとの予想もあります。
総括すると、知識蒸留はAIモデルのコスト効率とアクセス性を飛躍的に高める技術であり、DeepSeekの事例はその可能性を示しました。現時点でChatGPTを完全に凌駕するには至らないものの、蒸留によって生まれたオープンモデルが急速にキャッチアップしているのは事実です。今後、蒸留技術がさらに進歩し、大規模モデルの知識を余すところなく凝縮できるようになれば、「安価な小型モデルが高価な巨大モデルを追い越す」場面が現れるかもしれません。その鍵を握るのは、蒸留の巧拙と新たなアルゴリズムの開発、そしてオープンな研究コミュニティの協力と言えるでしょう。DeepSeek発のイノベーションとそれに続く知識蒸留の深化から、目が離せません。

コメント